Upscaling images in PDFs with Python
My New Year’s resolution for 2024 was to finally run a TTRPG. At GenCon that year, our group fell in love with Yazeba’s Bed & Breakfast. I decided this was the one. Yazeba’s is not a fully GM-less TTRPG, but it gives the “Concierge” many training wheels and few responsibilities. One of these is to serve as the group’s bookkeeper: I’d have to make a Ledger to keep character sheets and other printouts.
Unfortunately, I found that the images in the Ledger PDF were of very poor quality. They were compressed to a point where the compression artifacts were readily noticable even after printing.
This got me thinking: can we upscale these images to remove compression artifacts? Turns out, yes! There’s not much info out there about upscaling images embedded inside PDFs, so I figure there’s value in documenting my workflow as a tutorial.
But first, here’s an example of what’s possible with this method:

High-level overview of the steps involved:
- Extract images and their soft masks from the PDF
- Recombine the images with their soft masks
- Upscale (or otherwise process) extracted images
- Replace images in PDF with upscaled versions
Tools we will be using:
- Python 3.11.4 (or higher)
- MuPDF (via PyMuPDF)
- ImageMagick (via Wand)
- Waifu2x (via nunif-windows-package)
- Click
Download ledger.pdf from Yazeba’s on itch.io to follow along.
Let’s install Click, PyMuPDF and Wand into our environment now:
pip install click==8.1.8 pymupdf==1.24.9 wand==0.6.13Here is my script:
import click
import functools
import os
import shutil
import pymupdf
from pathlib import Path
from typing import Optional
from wand.image import Image
def common_params(func):
"""Decorator to store options common to both commands."""
@click.option(
"-i", "--pdf", "pdf_path",
help="Path to target PDF file",
required=True,
type=click.Path(
exists=True,
dir_okay=False,
writable=True,
resolve_path=True,
path_type=Path,
),
)
@click.option(
"-d", "--dir", "img_dir_path",
help="Path to image directory",
default=None,
type=click.Path(
file_okay=False,
writable=True,
resolve_path=True,
path_type=Path,
),
)
@click.option(
"-f", "--force", "force",
help="Don't prompt to overwrite files",
default=False,
is_flag=True,
)
# https://github.com/pallets/click/issues/108#issuecomment-280489786
@functools.wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
@click.group()
def cli():
"""Toolset for replacing images inside PDFs."""
@cli.command("extract")
@common_params
@click.option(
"-g", "--gray", "grayscale",
help="Extract as grayscale, not RGB",
default=False,
is_flag=True,
)
def extract_images(
pdf_path: Path,
img_dir_path: Optional[Path],
force: bool,
grayscale: bool,
):
"""Extract images from PDF into directory."""
if img_dir_path is None:
img_dir_path = get_default_img_dir_path(pdf_path)
# Exit if the dir exists and the user refuses to delete it
if (
img_dir_path.is_dir() and
not force and
not click.confirm(f"Delete existing image directory? ({img_dir_path})")
):
raise click.ClickException("Choose another image directory (-d)")
colorspace = pymupdf.csGRAY if grayscale else pymupdf.csRGB
# Reset/create the image directory
shutil.rmtree(img_dir_path, ignore_errors=True)
os.makedirs(img_dir_path)
with pymupdf.open(pdf_path) as doc:
for page in doc:
for image in page.get_images():
img_xref = image[0]
smask_xref = image[1]
img_path = img_dir_path / f"{img_xref}.png"
smask_path = img_dir_path / f"{img_xref}-smask.png"
img_pix = pymupdf.Pixmap(doc, img_xref)
img_pix = pymupdf.Pixmap(colorspace, img_pix)
img_pix.save(img_path, "PNG")
if smask_xref != 0:
smask_pix = pymupdf.Pixmap(doc, smask_xref)
smask_pix.save(smask_path, "PNG")
# Use Wand (ImageMagick) to combine SMask with image
with (
Image(filename=img_path) as src_img,
Image(filename=smask_path) as smask_img
):
# SMask could have different size than image
smask_img.resize(
width=src_img.width,
height=src_img.height,
)
src_img.composite(
image=smask_img,
left=0,
top=0,
operator='copy_alpha'
)
src_img.save(filename=img_path)
# Delete the SMask, we won't need it anymore
smask_path.unlink()
click.echo(f"Extracted images to {img_dir_path}")
@cli.command("replace")
@common_params
@click.option(
"-o", "--out", "out_path",
help="Path to output PDF",
default=None,
type=click.Path(
file_okay=False,
writable=True,
resolve_path=True,
path_type=Path,
),
)
def replace_images(
pdf_path: Path,
out_path: Optional[Path],
img_dir_path: Optional[Path],
force: bool,
):
"""Replace images in PDF from directory."""
if img_dir_path is None:
img_dir_path = get_default_img_dir_path(pdf_path)
if not img_dir_path.exists():
raise click.ClickException("Image directory does not exist")
if out_path is None:
out_path = get_default_out_path(pdf_path)
# Exit if the output PDF exists and the user refuses to delete it
if (
out_path.is_file() and
not force and
not click.confirm(f"Delete existing output PDF? ({out_path})")
):
raise click.ClickException("Choose another output path (-o)")
done_xrefs = []
with pymupdf.open(pdf_path) as doc:
for page in doc:
for image in page.get_images():
img_xref = image[0]
if img_xref not in done_xrefs:
img_path = img_dir_path / f"{img_xref}.png"
if os.path.exists(img_path):
page.replace_image(xref=img_xref, filename=img_path)
done_xrefs.append(img_xref)
doc.save(
filename=out_path,
garbage=4,
clean=1,
deflate=1,
deflate_images=1,
deflate_fonts=1,
)
click.echo(f"Saved PDF to {out_path}")
def get_default_img_dir_path(pdf_path: Path) -> Path:
return pdf_path.parent / (pdf_path.stem + "-images")
def get_default_out_path(pdf_path: Path) -> Path:
return pdf_path.parent / (pdf_path.stem + "-out" + pdf_path.suffix)
if __name__ == "__main__":
cli()Lots of Click-related boilerplate here, but it does a lot for us, like validating input and populating help. For example:
> python main.py extract --help
Usage: main.py extract [OPTIONS]
Extract images from PDF into directory.
Options:
-i, --pdf FILE Path to target PDF file [required]
-d, --dir DIRECTORY Path to image directory
-f, --force Don't prompt to overwrite files
-g, --gray Extract as grayscale, not RGB
--help Show this message and exit.Extract images from ./ledger.pdf into ./ledger-images/:
python main.py extract -i ledger.pdf -gWe export in grayscale (-g) because the source file is in grayscale, and this saves us roughly 50% filesize after upscaling vs. exporting in RGB.
Here’s our folder with extracted images:

Now, we can use whatever method we want to upscale or otherwise process the images. Upscaling is a huge topic—too big to do justice here. I’ll just talk through the tool I used for this project.

Waifu2x is an image scaling and noise reduction program for anime-style art. It’s a perfect fit for our use-case. Unlike many other upscaling solutions, it’s easy to get Waifu2x running locally as a stand-alone application.
Go download nunif-windows-package and follow the install instructions. Installation will take a while: it needs to download PyTorch and several trained models. My install took 8.3 GB of disk space!
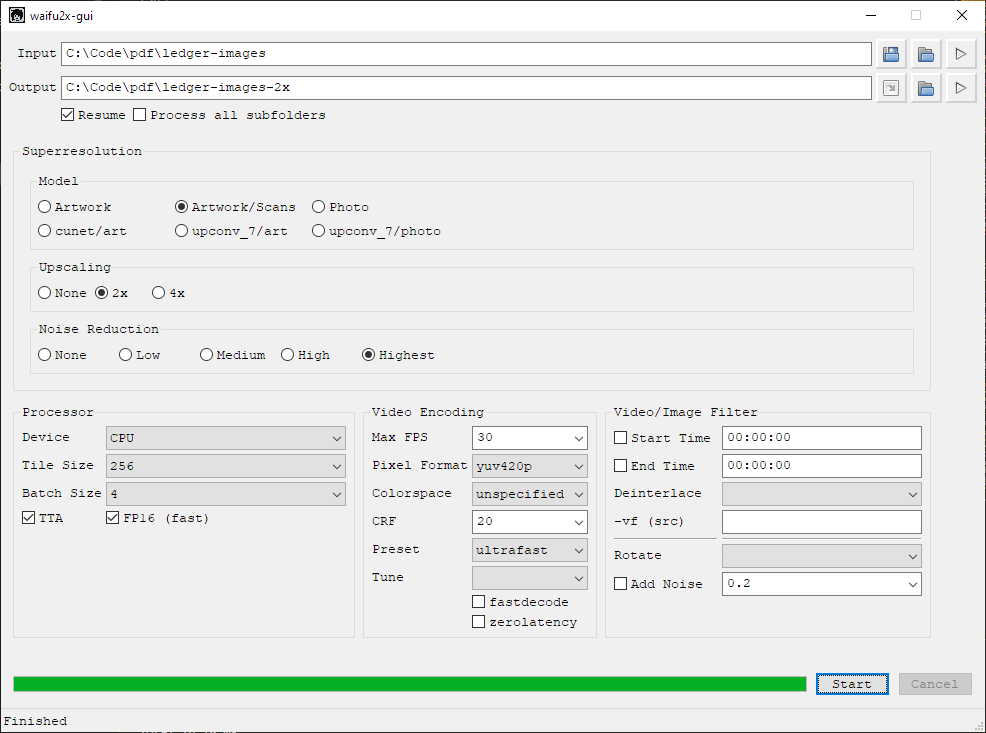
Once installed, launch waifu2x-gui.bat, then:
- Input > Choose a directory > Select
C:\path\to\ledger-images - Output > Enter a path to output, e.g.
C:\path\to\ledger-images-2x - Model > Artwork/Scans
- Upscaling > 2x
- Noise Reduction > Highest
- Processor > GPU (if available)
Some things to keep in mind:
- Output directory will be created if it does not exist. If it exists, Waifu2x will only process files which have not yet been processed, even if the settings changed. Uncheck “Resume” to disable this behavior.
- For Model, Upscaling, and Noise Reduction, these settings worked best for my use-case, but yours might be different. Play around with them.
- Waifu2x runs fast on GPU, but slowly on CPU. My screenshot shows CPU because I’m writing this up on an old laptop after the fact. Use GPU when available.
- Ignore the video settings.
Screenshot of Waifu2x settings:
We can now replace the images in the PDF with our upscaled versions:
python main.py replace -i ledger.pdf -d ledger-images-2xThis will output ./ledger-out.pdf with the images replaced. That’s that. We are done!
Now, I’m not telling the full story here. Every grayscale image in the Ledger PDF has a color version in the main rulebook PDF. After extracting images from both, I wrote a script to swap grayscale images for upscaled color ones. Some manual editing was required due to layout differences. Lastly, I experimented with color reduction using pngquant to reduce filesize.
All of that is too situational to detail here. The main takeaway is that once the images are extracted, you can do whatever you want with them before swapping them back into the document. Your needs will be specific to your situation, which is why this is a tutorial blog post and not a repo on GitHub. Good luck!
In my case, Waifu2x worked great for the color images too:

To close this out, here’s a photo of the finished ledger:

Yummy color and no compression artifacts. I think having color character sheets helps draw players into the characters. The art is beautiful here, and it feels right to put it in front of the players instead of keeping it to myself in the book. I’ve run four games of Yazeba’s so far, and I look forward to running more in the new year.